Hospitalized patient readmission prediction
Readmission rate is one of the key indicators for the hospitals to maintain their quality. In 2014, Medicare fined a record number of 2,610 hospitals for having too many patients return within a month for additional treatments. reference
Predicting readmission within 30 days is very critical not only for the hospitals. If a patient can see his readmission risks, he and his family can prepare and prevent unwanted readmission.
Objective: Predict readmission classes of patients discharged to home.
- Readmitted within 30 days of discharge
- Readmitted after 30 days of discharge
- No readmission (between 1999-2008)
Data
- 101,766 patients hospitalization records.
- The Health Facts data I used was an extract representing 10 years (1999–2008) of clinical care at 130 hospitals
Reference: Beata Strack, et al. BioMed Research International Volume 2014 (2014). Link
Machine Learning
I used these 24 features below to train readmission prediction algorithm. 'race', 'gender', 'ages', 'admission', 'discharge', 'admsource', 'time in hospital', 'payer code', 'num lab procedures', 'num procedures', 'num medications', 'number outpatient', 'number emergency', 'number inpatient', 'diag1', 'diag2' 'number diagnoses', 'max glu serum', 'A1Cresult', 'insulin', 'change', 'diabetesMed'
Developed algorithm predict one of three readmission classes(readmit within 30 days, readmit after 30 days, no readmission) from input of 24 feature data.
Building machine learning system
Medical diagnosis was categorized into 40 categories based on ICD-9 codes.
Data sets were split 4:1:5 (training set : validation set : testing set). After developing and validating prediction model with training and validation data sets, the prediction algorithm was applied to testing sets. Using python machine learning modules, I tested K-Nearest Neighbors, Logistic regression(with Lasso and Ridge regularization), Naive Bayes (Gaussian and Multinomial), Decision Tree, Support Vector Machine (Linear and RBF Kernel), RandomForest and GradientBoosting methods. Each algorithm showed different learning curve.
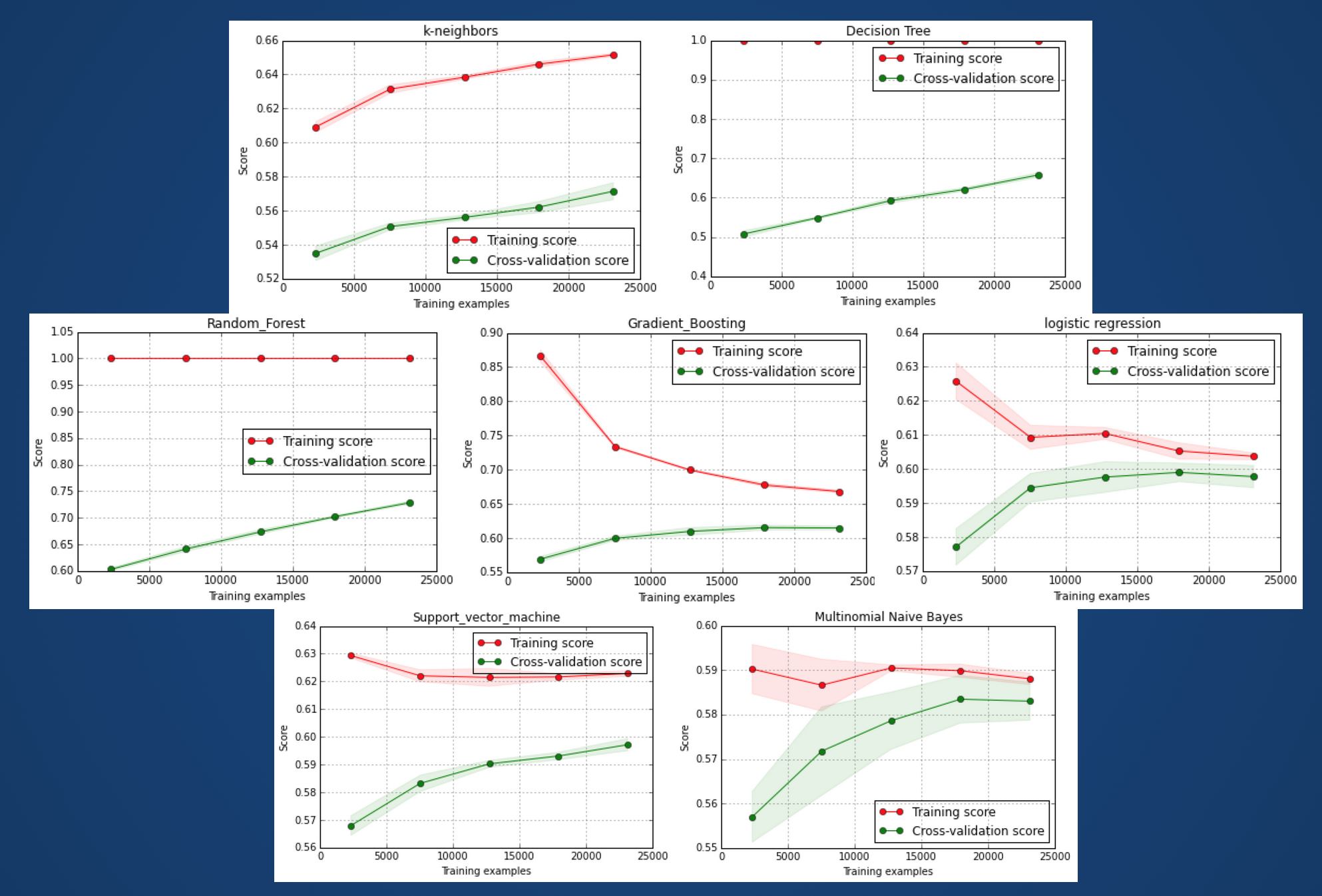
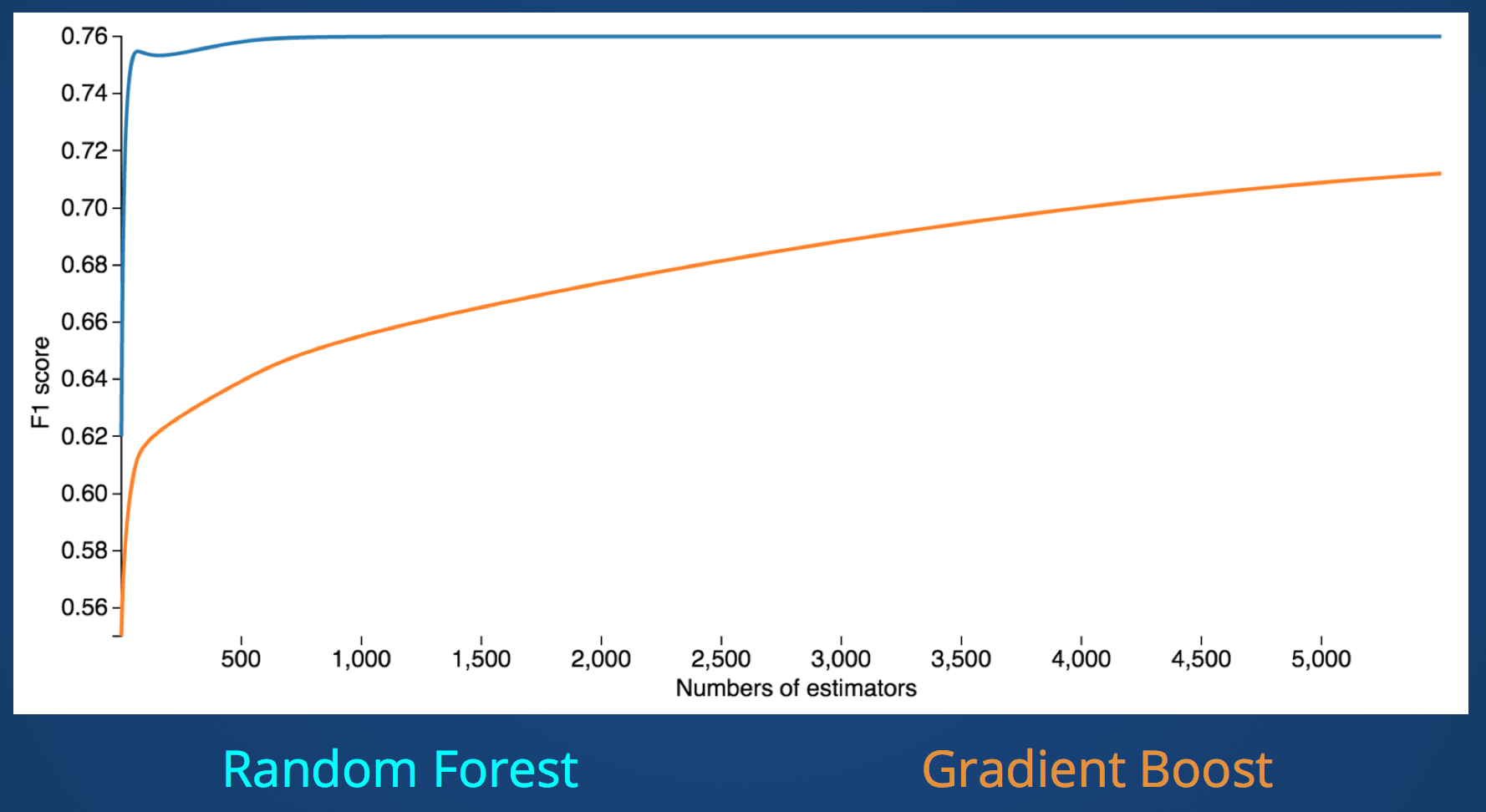
Each machine learning classifier algorithm has multiple parameters for tuning. For example Random Forest randomly chooses features to create each tree. So some of key parameters are: number of estimators (the number of trees in the forest), maximum number of features (start with sqrt(n features)), maximum depth of the tree.
Here is an example of tuning in Gradient Boosting and Random Forest model with number of estimators parameter. You can see gradual increase of F1 score (the harmonic mean of precision and recall) with the increase of the number of estimators. Random Forest becomes stable more than several hundreds.
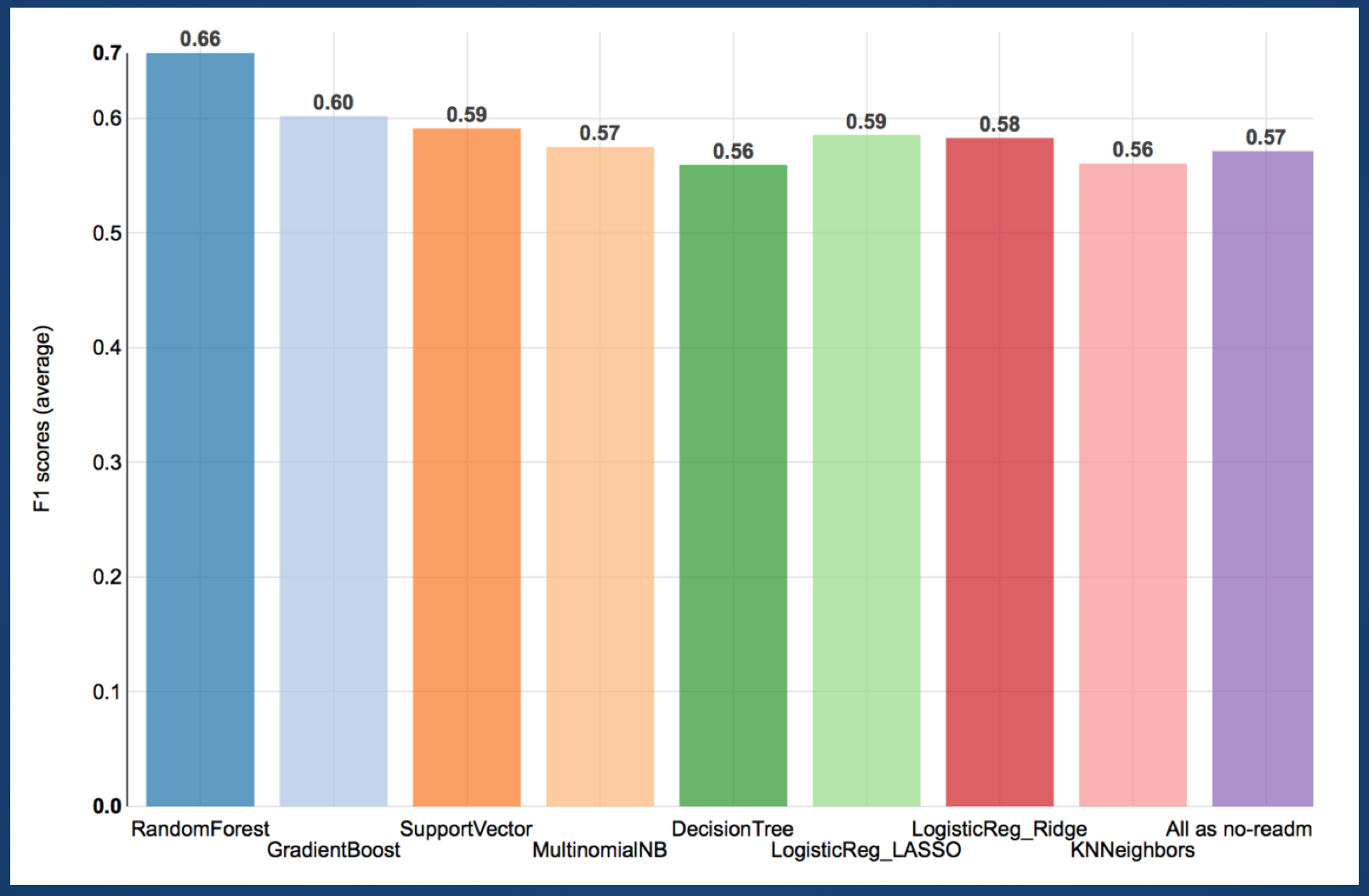
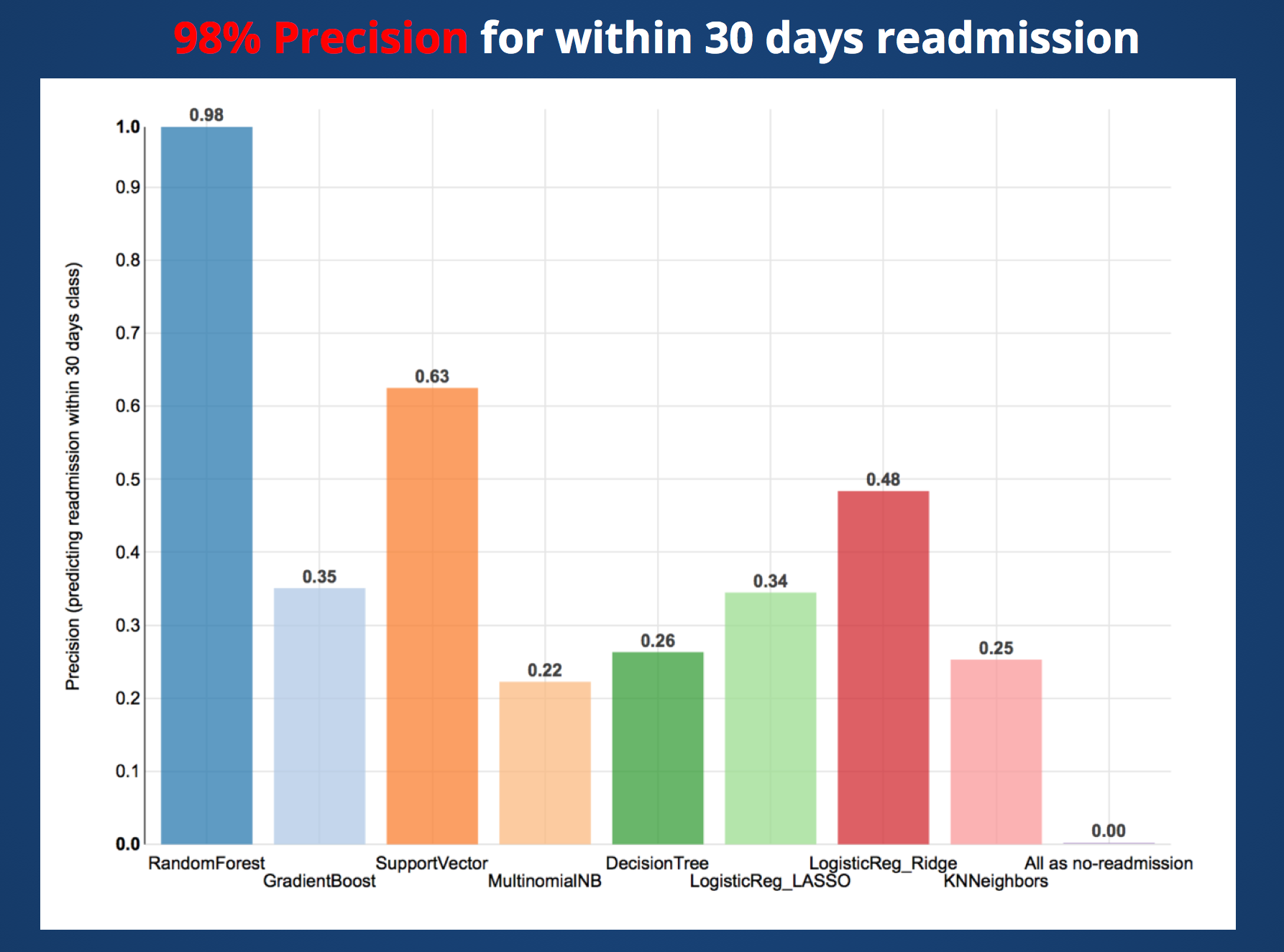
RandomForest model was the highest F1 score (average of three classes, readmitted >30days, readmitted <30days, not readmitted).
 Then I checked actual predicted categories numbers from each algorithm to see if there are some interesting findings.
Then I checked actual predicted categories numbers from each algorithm to see if there are some interesting findings.
Predicting patients who would be readmitted within 30 days
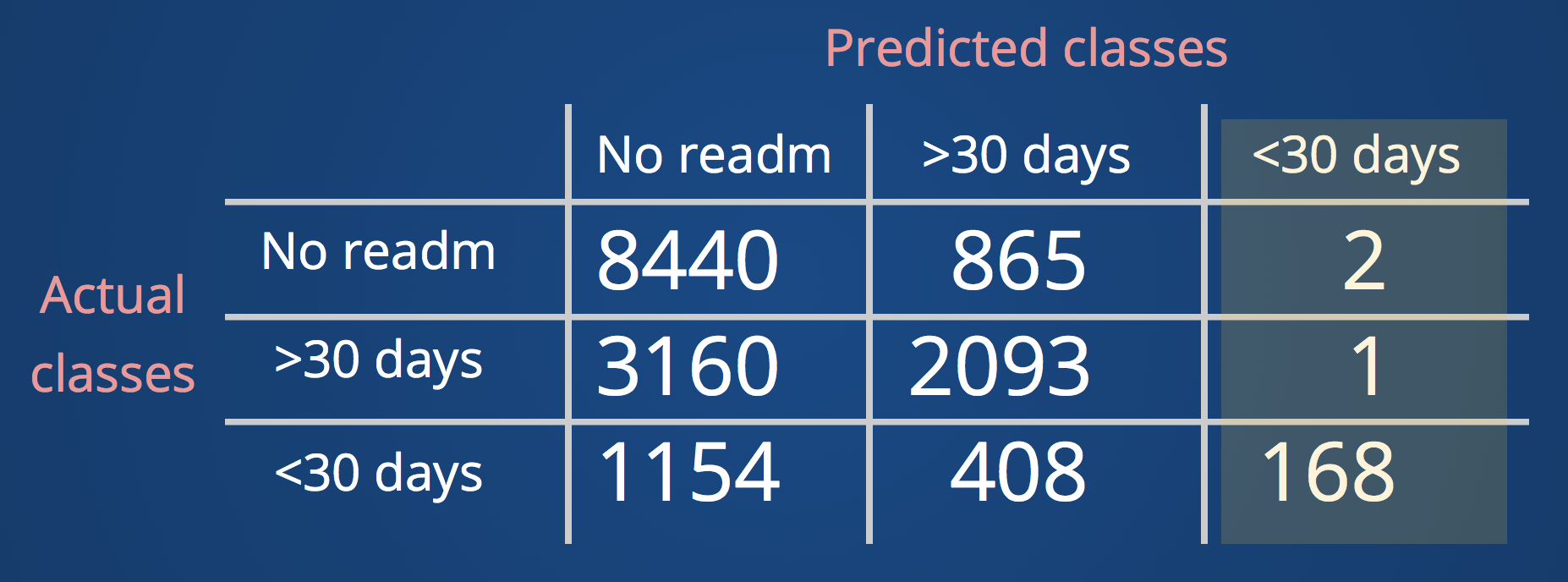
By checking confusion matrix from each algorithm, I found very different patterns. Averaged Accuracy, Recall, Precision, F1 scores are similar among models. On the other hand the scores for each output classes were quite different. Then I went back and thought about predicting readmission in real life.
In real situation, patients and hospitals pay closer attention to people readmitted within 30 days category because it would be worst experience compared to other after 30 days or no-readmission case. So if algorithm can predict within 30 days readmission event with high precision, that should be most helpful for both hospital and patients.
The precision with Random Forest based algorithm was very high 0.98 (168 out of 171 prediction was true).
I believe this algorithm would be a useful predictor.
At the same time we need to pay attention to Recall score is low in this prediction 0.10 (168 out of actual 1730 within 30days readmission cases).
This algorithm predicts patient readmitted within 30 days with 98% precision and it covers 10% of within 30 days readmission patient population.
Check confusion matrix(RandomForest model).
Top18 important features for readmission classification.
The top 3 features are would solid association: "number of lab test performed", "number of procedures performed during the encounter" and "number of given medication". On the other hand, features after top 10 are very interesting. "Given same insulin dosage", "secondary diagnosis as circulatory or diabetes" and "payer code" play a certain role in this model. I believe obtaining more data and with more research about these factors may help decreasing the readmission rate. Finally I want to clearly state that these features are important for prediction algorithm, but not proving causation.

num-lab-procedures: Number of lab tests performed during the encounter, num-procedures: Number of procedures (other than lab tests) performed during the encounter, num-medication: Number of distinct generic names administered during the encounter, number-outpatient: Number of outpatient visits of the patient in the year preceding the encounter, number-emergency: Number of emergency visits of the patient in the year preceding the encounter, number-inpatient: Number of inpatient visits of the patient in the year preceding the encounter, number-diagnoses: Number of diagnoses entered to the system, change of medication: Indicates if there was a change in diabetic medications